
Update: I published an update to this article about some of the changes to Basic Man over the past five months.
Several months ago, I decided to build a website for men’s skincare, beauty, and style products - it would provide a easy way for men to purchase a variety of essential products (shampoo, conditioner, moisturizer, etc.), and would offer a single recommendation for each category. I wanted a one-stop place where you could acquire these essentials, knowing that they would enjoy the products purchased as they had been curated and tested by other men. Avoiding the “I’m in the supermarket, which of these 40 different products do I really need” situation, if you will.
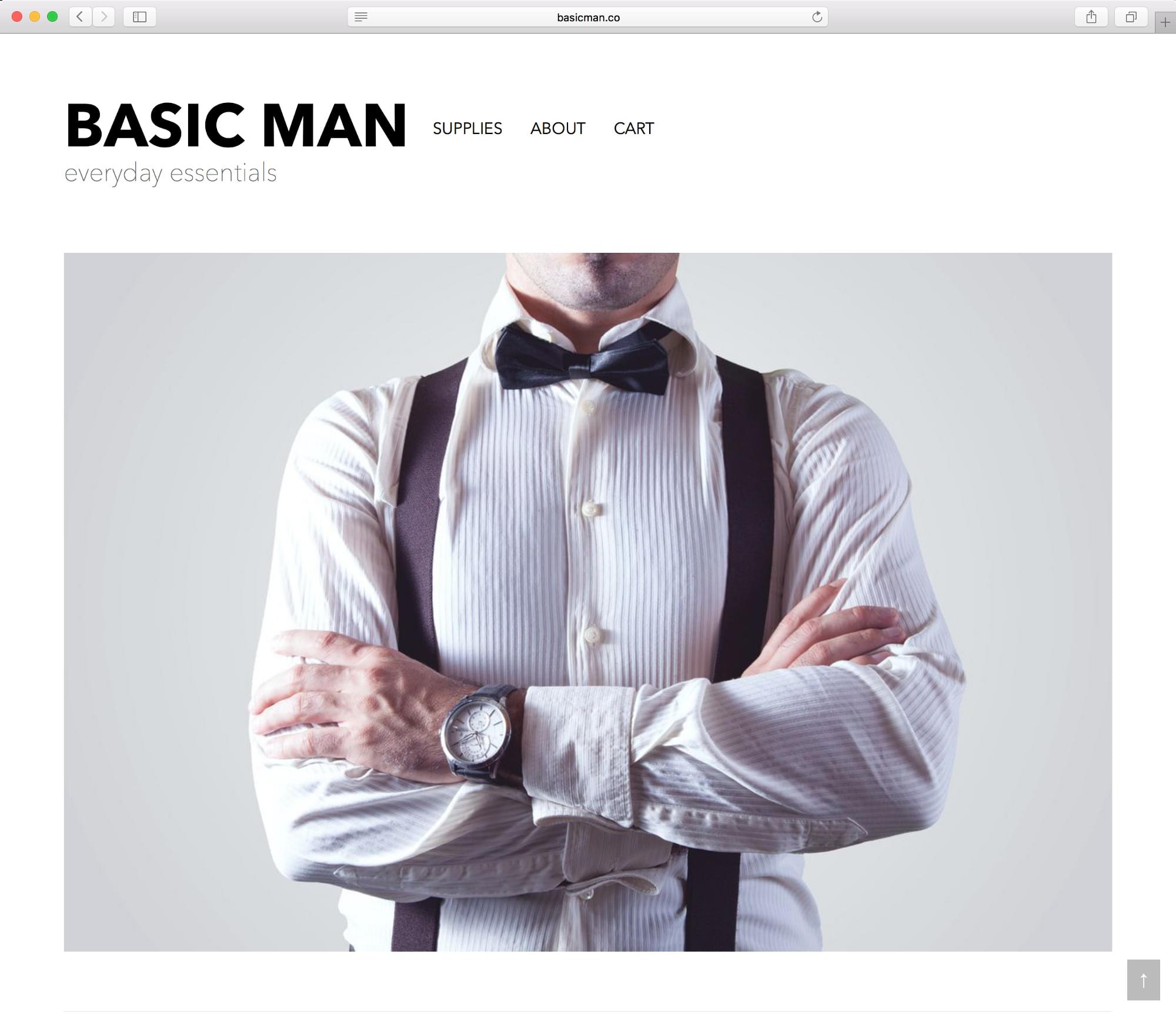
BasicMan.co launched today after many spare weekends of work, and while it’s definitely far from perfect, I’m happy with the start.
Besides building a convenient resource, I wanted to exercise some newly-learned technologies and stretch their boundaries a bit to create a product that was technically solid as well as useful. Here are some of the details, presented in the hopes that you may find them informative and interesting:
Architecture
BasicMan.co’s architecture is a basic API / static frontend application, with a few twists:
- A static YAML file to act as the “database”
- Shopping cart functionality by the Amazon 1. Product Advertising API
- Heroku to power a backend cart API
- GitHub Pages to serve a static frontend (hybrid React/SPF.js app)
YAML File Database
So, the YAML file isn’t a database in the traditional sense, but it does act as a read-only data store. The majority of the website content is stored in that single YAML file. The categories, their names, descriptions, slugs, and their products, with names, prices, descriptions, features, etc. are all formatted in a YAML file. This makes it fairly trivial to edit any content on the website, and also facilitates data sharing between the frontend and the API, as both can read directly from the file on disk.
The YAML file looks something like this:
category-id:
name: Category Name
description: >
<p>
Category description
</p>
products:
- asin: 'xxxxxxxxxxxxxxxx'
offerID: 'xxxxxxxxxxxxxxxx'
slug: 'item-slug'
name: 'Item Name'
price: 8.99
description: >
<p>Item Description.</p>
why:
- Info about why this item was chosen.
directions:
- Info or tips about how best to useAmazon Product Advertising API
Amazon offers its “Associate Program,” which allows publishers to link to Amazon items or pages or promotions and receive a commission for any completed sales. As a part of this program, they offer a Product Advertising API which allows for searching Amazon programmatically, but most importantly for my use-case, it allows for the management of remote shopping carts.
These remote shopping carts allow you to add items, change quantities, and remove items, then when the user is ready to checkout, redirect to Amazon.com with their shopping cart already filled in with the items from the remote cart.
Amazon manages everything, so this was perfect for my app. I could offer users a quick way to add all the items they needed in one place - they don’t even have to leave the homepage - and I didn’t need to write any complex cart logic, process payments, house inventory, or manage shipping (I’m just trying to be a resource, not a full-blown eCommerce business).
Backend API
I did, however, need to secure access to the Amazon cart API. This was fairly easy to accomplish with a Node.js/Express API server that essentially exposed the Amazon API in “safe” endpoints. Those endpoints are the following:
/cart- view the current state of the cart/add/:item- add an item to the cart/change/:item/:quantity- adjust the quantity of item to :quantity/remove/:item- remove all of item from the cart/clear- remove everything from the cart
These endpoints essentially wrap calls to the Amazon API and standardize the responses in a format that the frontend can utilize.
I used a simple cookie-based session where any request to the API gets assigned a cookie and the user’s remote cart ID is attached to that session.
Note: Third-Party Cookies and Mobile Safari
Mobile Safari blocks third-party cookies. This means that every time the website tries to add an item to the cart from an iPhone or iPad, it will succeed, but the cart ID will be lost and the user will not ever be able to checkout. This happens because the user accesses the site at basicman.co, the first-party domain, and the cookie is coming from api.basicman.co, the third-party domain.
The workaround to this is to redirect to the API server, making it the first-party domain rather than the third-party one, store the cookie, and redirect back to the original website. This is accomplished via something like this:
- Call a special endpoint on the API server that returns true if a session cookie was sent from the browser and false otherwise
- If there is no session cookie, redirect to api.basicman.co
- The API server will respond with a Set-Cookie header as well as a redirect back to basicman.co
- The frontend will call the special API endpoint again, which will report the presence of the cookie, and all future API calls will be under that same session
As a workaround for browsers that do not store cookies, the backend appends a URL hash value to the redirect that the frontend interprets to mean that it shouldn’t check for the session cookie. This allows tools like Google PageSpeed Insights to function, but does not however allow the site to work without cookies. For now, it’s broken without them.
Static Frontend
The frontend pages are generated with the Middleman gem, as it provided the easiest solution to turn a static data file (the YAML file) into separate pages. A one-to-many static site generator, if you will. Middleman offers proxy pages, which do just that, using a configuration similar to the following:
data.categories.each do |_id, data|
data.products.each do |product|
proxy(
"/#{product.slug}/index.html",
'/products/template.html',
locals: { product: product },
layout: 'layout',
ignore: true
)
end
endThe homepage, about page, cart page, and product pages are all generated with the middleman gem in this fashion. Middleman includes the sprockets asset pipeline, which I utilized for images, but for JavaScript and CSS opted to use webpack for better JavaScript ecosystem support. Middleman provides a basic guide for integrating with external build pipelines that made it super easy to set up. Maybe in the future I’ll move the static generation to something in the Node realm to drop one more language dependency, but for now it is functional.
For overall design and layout, I used flexbox and opted not to use any CSS frameworks. This resulted in small CSS files, and flexbox made responsive layout painless. I’d highly encourage you to check it out, especially if you can afford to drop support for IE9 (which should be very doable considering it has less that one percent of the market share and is no longer supported by MS).
For the dynamic elements of the website, bring on the buzzwords: Webpack, React, Redux, Babel, ES6–7, SPF.js, unicorns, etc. (last one was imaginary).
Webpack + Babel packaged the app into something usable for the browser, transforming the ES6–7 syntax and combining and minifying all the dependencies into a common file. With several loaders and the extract-text-webpack-plugin, webpack also built the SASS stylesheets into plain CSS and automatically prefixed them for older browsers with autoprefixer.
React supplied the dynamic elements of the website - the add-to-cart buttons and the cart page itself. I build three React components total:
AddToCart- a standalone add-to-cart button that appears next to each product on the homepage and on each product detail pageCart- the cart itself from the cart pageCartCount- the small number next to the cart link in the navigation indicating how many items were inside the cart
I probably should have split the Cart component itself into a parent Cart with sub “CartItem” and “CartAction” components, etc., in order to be truly “react-like,” however what I have is functional and at the end of the day that’s what matters.
Redux provided the basic application data flow architecture, which essentially consisted of fetching the cart state on load, then fetching the cart state again after various actions like add to cart or adjust quantity were sent to the server. I won’t go into detail about redux other than to say it’s awesome and you should read about it, but if you’re curious, here’s the entirety of the cart redux code.
So, the big question for me was how do I combine a statically-generated site with react for dynamic elements?
What I landed on was SPF.js. SPF (structured page fragments) is similar to libraries like pjax or Turbolinks in that it is a JavaScript library that makes special requests to a server and updates part of the page in-place from the HTML returned from that server. It was written by YouTube. It differs from other solutions in that it accepts a structured JSON response telling it which areas of the page need updating and what the new HTML should be. It exposes several events throughout the request lifecycle. Putting all this together, I improvised a basic system that binds and unbinds React on demand based on SPF navigation.
First, I set up a map between HTML class names and React components. Something like:
const reactRootMap = {
'react-AddToCart': AddToCart,
'react-Cart': Cart,
'react-CartCount': CartCount,
}Next I created a function to dynamically bind elements on the page:
const bindReact = (store) => {
Object.keys(reactRootMap).forEach((className) => {
const elements = Array.from(document.getElementsByClassName(className))
const DynamicComponent = reactRootMap[className]
elements.forEach((rootElement) => {
const dynamicProps = {}
const attrs = rootElement.attributes
for (let i = attrs.length - 1; i >= 0; i--) {
const {name, value} = attrs[i]
const match = name.match(/data-react-(.*)/)
if (match) dynamicProps[match[1]] = value
}
ReactDOM.render(
<Provider store={store}>
<DynamicComponent {...dynamicProps} />
</Provider>,
rootElement,
)
})
})
}It essentially just finds elements by class name, matches them to components from the map, and binds a Redux Provider with the dynamic component inside. It also allows dynamic props with the data-react-propname attribute pattern.
Next I created a function to unbind all roots on the page:
const unbindReact = () => {
Object.keys(reactRootMap).forEach((className) => {
const elements = Array.from(document.getElementsByClassName(className))
elements.forEach((rootElement) => {
ReactDOM.unmountComponentAtNode(rootElement)
})
})
}With these in place, I just had to listen to the SPF events (spfdone for page load, and spfprocess for the start of HTML replacement) and bind / unbind the React elements on demand.
Thus the application felt like a single-page-application, and more importantly, did not have to re-fetch the state from the server on every page change. The overall Redux store maintained its state, and React components quickly joined and left the application as needed.
SPF requires a certain format for the JSON response to know what elements to update. I used a subset of the possible fields:
{
"title": "Page Title",
"body": {
"container": "HTML goes here"
}
}This instructs SPF to update the page title and to find an element with the ID container and fill it with the submitted HTML.
Using Middleman, I created a JSON file for every HTML file in the above format. I wrote a Middleman extension to accomplish this, and at some point I may open-source this as a gem, however for now it’s quite unpolished and brittle.
The final step in configuring SPF was to adjust its url-identifier setting to be -spf.json, meaning a URL like basicman.co/about would get requested as basicman.co/about-spf.json, fetching the custom-generated static JSON.
Putting all this together, BasicMan.co was a working application.
Deploying this to GitHub pages was just a matter of configuring Circle CI (used for continuous integration) to run the following deploy script on every successful build of master:
#!/usr/bin/env bash
# Push built files to gh-pages
cd build
cp -r ../.git .
git fetch origin
git reset --soft origin/gh-pages
git add -A
git commit -am "Automated deploy $(date)" --allow-empty
git checkout -b gh-pages
git push origin gh-pages
rm -rf .gitPerformance Optimization
I wanted to see how far I could push performance and optimization, and while I have not gotten as far as I’d like, I did learn several interested strategies along the way.
Firstly, the SPF / React strategy from above allows data fetching to happen in a performant way, since the initial cart state is loaded once on the initial page load and is retained as the user navigates around the site.
I set up a CDN with a personal account on MaxCDN and configured asset hashes in Middleman. This allowed the app assets to be cached with a far-future date by the fast CDN. Then when the asset contents change, their names change as well.
For product images, I set up a script to build optimized sizes and compress them for small file sizes:
#!/usr/bin/env bash
cd ./source./products/source
for i in *jpg; do
echo "Building $i"
convert "$i" -resize 600x900 -gravity center -extent 600x900 "../versions/rectangle-$i"
convert "$i" -resize 360x360 -gravity center -extent 360x360 "../versions/square-$i"
convert "$i" -resize 100x100 -gravity center -extent 100x100 "../versions/square-small-$i"
done
cd ..
for i in ./versions/*.jpg; do
echo "Optimizing $i"
# Lossy
jpegoptim --max=80 --strip-all --all-progressive "$i"
# Lossless
# jpegtran -copy none -progressive -optimize "$i" > "$i.optim"
# mv "$i.optim" "$i"
doneFor icons and logos, I used inline SVG, which utilizes far less bandwidth than an equivalent image and automatically provides support for hi-DPI screens. Additionally, inlining them in the HTML prevented an additional network request. The cart images (small versions of the product images that show up in the cart) are base64’d and sent inside the cart API response so as to avoid additional requests and issues with the asset hashes.
A small “seed” stylesheet was inlined in the <head> that displays a loading SVG icon over the entire page, and then added the primary stylesheet via async JS near the end of the <body>. This reduces the time it takes for the browser to render the initial page view. Once the full stylesheet loads, it has rules that hide the loading splash.
All JavaScript was made non-blocking.
Taking the optimization further, I would like to optimize for the rendering of the initial visible content and make it should that no additional network requests beyond the first HTML page are required for that initial viewing window (this is recommended by PageSpeed). The large image on the homepage was inlined with a base64 URL (automatically generated with Middleman) so as to reduce that network request. I still need to move more of the CSS from the primary stylesheet into the seed stylesheet in order to fully achieve the one-request-to-visible goal.
All fonts were chosen from options already installed on users’ computers to reduce a dependency on a webfont. I really like the font choice available on Mac and iOS devices (Avenir Next) and am tolerating the choice available on Windows or Android (Arial). I may consider adding a webfont fallback if the user is on a device missing Avenir Next, but for now haven’t set that up.
Third-party JavaScript was reduced to just Google Analytics.
Conclusion
I’m happy with what I’ve built so far and look forward to continuing to optimize / polish. Web technologies are growing and maturing at a rapid pace, and the speed at which this project was developed is a testament to the many smart engineers who have been moving the web forward.
If you’re a guy or need to buy essentials for a guy, feel free to check out BasicMan.co. And if you have any anecdotes, product recommendations, technical advice, or feedback of any kind, it is always welcome!